
Overview
Ya.Digital Project by Yarmarka and abgroup.tech Nominated for Data Award 2026

Development of a Data Lakehouse architectural scheme for a construction holding company
One of
the leading construction holdings in the Russian Federation has asked us to develop a promising data platform designed to collect, analyze and consolidate data from various accounting systems and file sources.
The purpose of the platform is to provide subsequent data visualization using a variety of analytical tools.
At the time of the start of the project, the company lacked an analytical infrastructure. There was only a set of accounting systems without a centralized data warehouse. The scope of the project and its specific requirements, including a completely closed access loop through terminal solutions, were not fully clear.
It was decided to use the Data Lakehouse architecture based on open source code.
The following products were selected as key components of this architecture:
· Apache Kafka
· Dagster
· S3 + Iceber
· Trino
· ClickHouse
· DBT.
As a result of the project, more than 1,000 DBT models were created, and the volume of compressed data at the start was more than 1 terabyte with further increase.
Data consumers include business systems, Power BI reports, web applications and MDX cubes, analysts and data scientists.
The project implementation methodology is Scrum. The development team includes 11 specialists in the design and development of data warehouses (DWH engineers). The project was implemented from scratch (greenfield development).
Consider the architectural scheme:
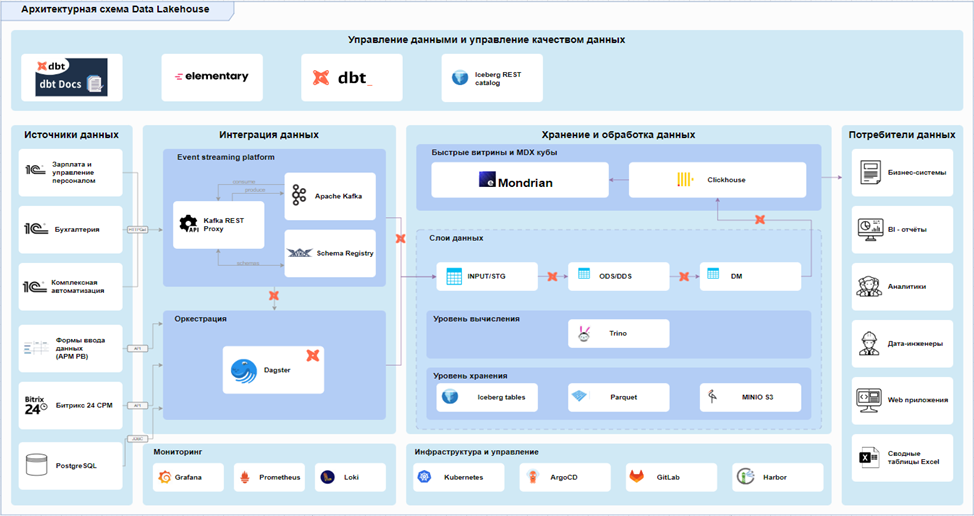
The scheme on the left shows the data sources: several 1C configurations (15 databases - 1C ZUP, 3 databases - 1C accounting and 1 database - 1C integrated automation). To integrate a huge amount of Excel data, we decided to use the Input Forms service developed by us. It automates the process of collecting and uploading both manual input data and data from Excel files.
Apache Kafka is used to integrate all 1C databases, providing a convenient, easily scalable process.
How does this happen?
A data exchange plan for 1C is being developed, rolled out and tested. The created extension implements a subscription to events for creating and modifying 1C objects with an entry in the queue for sending. Sending implements http requests to Kafka Rest, where they are validated using the kafka schema registry and written to the appropriate topics, from where the data is transferred to the storage.
Convenience of the approach:
1. allows you to scale quickly by connecting new 1C databases,
2. Provides good performance,
3. Assigns responsibility for sending data and compliance with the data contract to the source.
The data layers and the storage itself are built on the basis of Trino using open storage formats – Iceberg tables and object storage based on Minio S3.
Standard set of layers:
• STAGE - for loading raw data in append-only mode
• ODS - for cleaning, deduplication and typing
• DDS - Detailed data storage layer
• DM - for creating data storefronts
The showcase layer is uploaded to ClickHouse, which is a single data access point for business users and various business applications.
In this architecture, the eMondrian component is designed for business users who are used to working with tables in Microsoft Excel and creating summary reports based on multidimensional OLAP cubes. The main function of this component is to convert MDX queries from Excel to SQL queries, which are then routed to ClickHouse data storefronts. This process is carried out in real time, providing users with the opportunity to quickly access analytical information.
All services are deployed in a Kubernetes cluster, and we use Argo CD, Gitlab, and Harbor for the ci/cd process. For monitoring – Loki, Prometheus, Grafana.
The most important component of the presented approach is the DBT (Data Build Tool). The diagram shows that all transitions from component to component are carried out using it.
Elementary is an add–on over DBT that allows you to collect and visualize statistics on DBT project launches, test execution, and model materialization time.
Kafka – why is it needed?
As mentioned earlier, Kafka is the main bus for integrating various 1C platforms.
• Provides data acquisition and storage from a large number of 1C databases;
• Allows you to quickly scale the system by integrating new databases with identical configuration;
• Ensures correct processing and compliance of the received data with the registered data schema;
• Supports Avro format, which allows efficient processing and saving of large amounts of data;
• Provides easy and convenient integration with Trino;
• Trino has the ability to read Avro topics, while deploying and typing the entire nested data structure, eliminating the need for conversion to JSON format;
• Kafka topics can serve as a data source for DBT.
Dagster: Why not Airflow?
It was decided to use Dagster because of its seamless integration with DBT, which is very convenient and fast. The asset-level dependency management approach, user-friendly functional interface, in general, I wanted something new, since Airflow was used in all projects. Dagster has become a breath of fresh air for data engineers.
Trino
A single SQL engine that provides data transfer and transformation between storage nodes. It has many integrations, both with relational and non-relational sources, and works great with DBT (DBT has an adapter to Trino). Version 1.9 adds support for the microbatch strategy, which helps to save resources when working with large tables.
ClickHouse
The column database, designed for fast selections and aggregations, is great for BI systems that use direct database queries. It is also connected to Trino as a catalog, and in our case is the source for eMondrian.
DBT (Data build tool)
DBT is based on the Create Table As Select (CTAS) approach. All data modeling and transformation processes go through code. The use of incremental strategies, code reuse, GIT versioning, documentation automation, tests, and data contracts are all things that we love and value DBT for.
What does a DBT project consist of?
• dbt models (sql scripts and yml files) – describing entities
• Sources – description of sources (source.yml)
• Macros – sql scripts with jinja templating
• Seeds – csv files that can be referenced in models
• Tests – user tests
• dbt_project.yml – describes the entire project in full
• profiles.yml – describes the connection to the database
What are DBT models?
These are regular SQL queries in the form of CTE. Below you can see a fairly extensive DM layer model and a Yml file (description of this model). Both of these files represent the DBT model. In the Yml file, we fully describe our model and provide the necessary instructions for its execution, which columns it consists of, a description of these columns, data types, type of materialization, and other attributes.
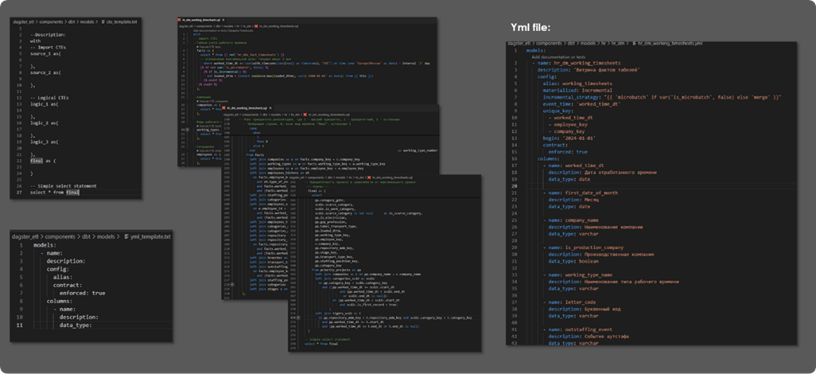
DBT-docs is a service that allows you to deploy a real documentation portal for your project, providing users with the ability to quickly search for necessary information on project models, see their dependencies, which macros are used, source and compiled code.
DBT Lineage is what allows us, developers and analysts, to quickly understand the essence of what is happening in the repository. Understand what the data depends on, how the showcase is built, and from what sources. You can click on the required model and go to its documentation page.
How do macros work in DBT?
Macros in DBT are a powerful tool for reusing SQL logic. It avoids duplication, simplifies code maintenance, and makes it more flexible.
Take, for example, the columns_as_yaml macro, which we often use in our projects.
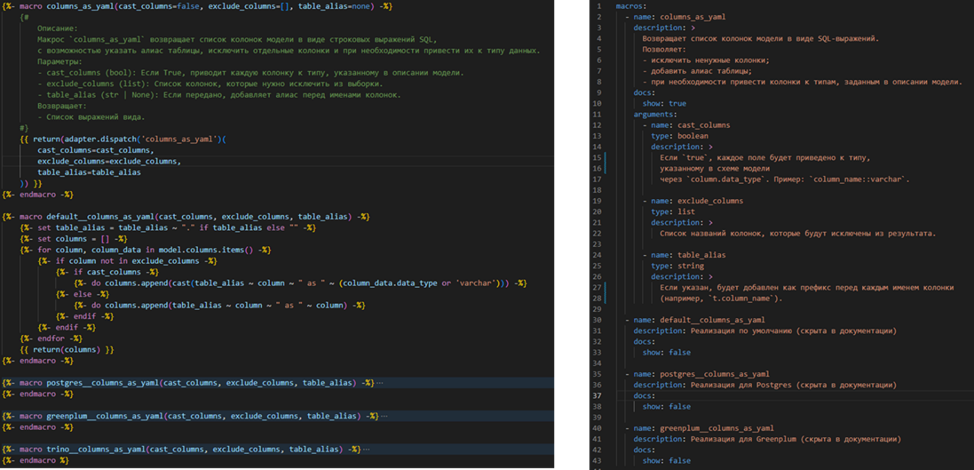
The screenshot shows the Jinja code and the yaml description of the macro that will be used in the documentation.
How the macro is called: we write the name of the macro in curly brackets. In this case, the macro uses the yaml file of the model, parses it, determines which columns are used in the file, and what types they have. This macro types the columns at the output in the final selection.
Macros can call other macros, consist of a large number, form cascades, forming frameworks for working with models.
There are many packages (sets of macros) on the DBT website that you can use in your work, but you can also write your own.
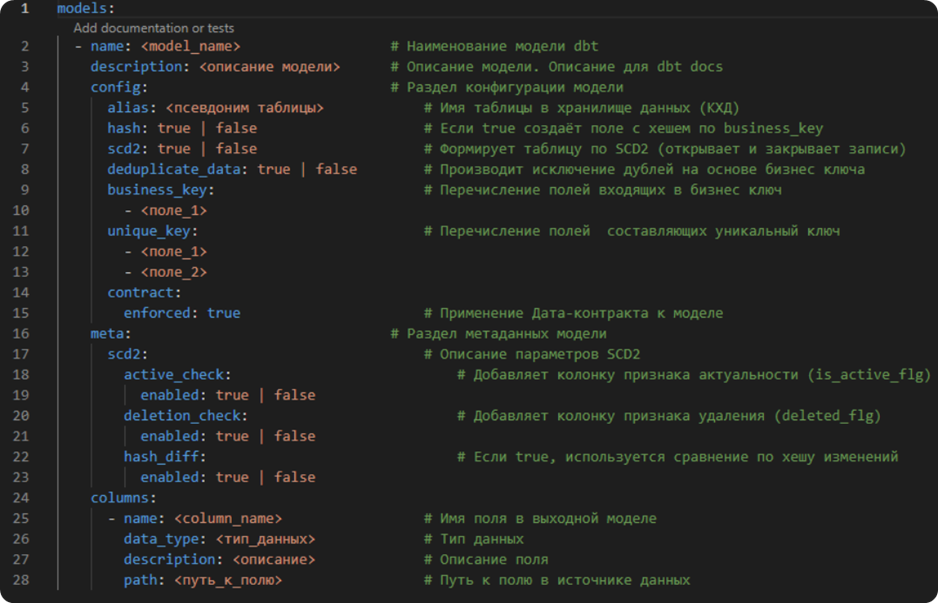
As an example, our package, which we use to build the ODS layer.
Opportunities:
• Flexible model configuration depending on the DWH modeling methodology
• Reduction of nested structures to a flat table
• Typing
• Elimination of duplicates
• Hash generation
• SCD2 implementation
• Tracking deleted records on the source
A detailed analysis of the examples in the video: https://vk.com/video-147838266_456239849
Modeling of the DDS layer using the Data Vault methodology
Many people know what Data Vault is and its advantages. However, there are disadvantages, one of them is a rather complicated conceptual implementation. For successful implementation and work with it, it is necessary to use external tools. Package automate_dv and DBT help to implement this.
Unit-tests
Using a large number of DBT macros, it's worth thinking about how to test them, because they contain a huge amount of logic. When making changes and improvements, you need to make sure that the expected result does not change. In our approach, the macro tests are implemented in a separate isolated project. The environment is created via Docker, a test database is used, as well as a set of fixtures for validating the results.
Advantages of a separate environment:
• Isolation: tests are independent of the product
• Reproducibility: Docker provides the same environment for tests
• Reuse: one macro, many cases
• Control: fixtures (input/output) are transparently compared
Things to keep in mind:
• Regulations, documentation, and articles for “how to do" developers.
• Metrics in grafana, alerts in TG and JIRA tickets.
• Iceberg tables require maintenance and configuration.
• Code-style, linters in CI, formatting of compiled code.
• The code review process.
• DryRun launches the DBT project in CI.
• Unit tests macros in CI.

